---
title: "Data Transform"
subtitle: 《区域水环境污染数据分析实践》
Data analysis practice of regional water environment pollution
author: 苏命、王为东
中国科学院大学资源与环境学院
中国科学院生态环境研究中心
date: today
lang: zh
format:
revealjs:
theme: dark
slide-number: true
chalkboard:
buttons: true
preview-links: auto
lang: zh
toc: true
toc-depth: 1
toc-title: 大纲
logo: ./_extensions/inst/img/ucaslogo.png
css: ./_extensions/inst/css/revealjs.css
pointer:
key: "p"
color: "#32cd32"
pointerSize: 18
revealjs-plugins:
- pointer
filters:
- d2
---
```{r}
#| echo: false
knitr::opts_chunk$set(echo = TRUE)
source("../../coding/_common.R")
library(nycflights13)
library(tidyverse)
```
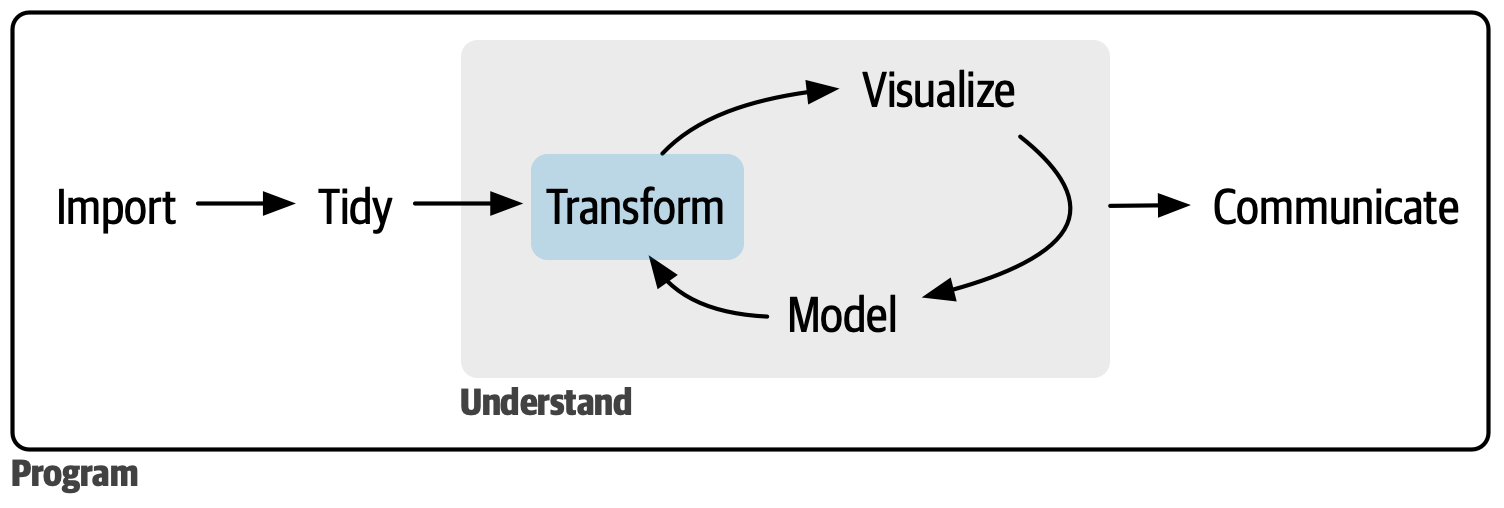
## `tidyverse`风格数据分析总体流程
## [dplyr cheatsheet](../../image/cheatsheet/data-transformation.pdf)
```{r}
#| echo: false
dwfun::ggsavep("../../image/cheatsheet/data-transformation.svg", loadit = TRUE)
```
## 查看数据
```{r}
flights
```
## 选择列
```{r}
#| results: false
flights |>
select(year, month, day)
```
## 选择列
```{r}
#| results: false
flights |>
select(year:day)
```
## 选择列
```{r}
flights |>
select(3:5)
```
## 选择列
```{r}
flights |>
select(!year:day)
```
## 选择列
```{r}
flights |>
select(-(year:day))
```
## 选择列
```{r}
flights |>
select(where(is.character))
```
## 选择列
```{r}
flights |>
select(!where(is.character)) |>
select(contains("_"))
```
## 选择列
```{r}
flights |>
select(tail_num = tailnum)
```
## 选择列
```{r}
flights |>
select(air_time, everything())
```
## 重命名
```{r}
flights |>
rename(tail_num = tailnum)
```
## 重命名
```{r}
flights |>
rename(年份 = 1) |>
rename(月份 = 2)
```
## 重命名
```{r}
flights |> select(1:4) |> head(n = 3)
# 重命名
flights |> select(1:4) |> head(n = 3) |>
rename_all(~c("c1", "c2", "c3", "c4"))
```
## 重命名
```{r}
flights |> select(1:4) |> head(n = 3)
# 重命名
flights |> select(1:4) |> head(n = 3) |>
rename_all(toupper)
```
## 重命名
```{r}
flights |> select(1:4) |> head(n = 3)
# 重命名
flights |> select(1:4) |> head(n = 3) |>
rename_all(~paste0(toupper(.), "_NEW"))
```
## 练习
将含有下划线的列名中的下划线去掉。
```{r}
flights |> select(1:4) |> head(n = 3)
```
## 练习
将`airqualitydf`中列名的单位信息去除(前5列)。
```{r}
airqualitydf <- readxl::read_xlsx("../../data/airquality.xlsx", sheet = 2)
airqualitydf |> select(1:5)
```
## `filter`
```{r}
flights |>
filter(dep_delay > 120)
```
## filter 练习
Flights that departed on January 1.
```{r}
#| echo: false
flights |>
filter(month == 1 & day == 1)
```
## filter 练习
Select flights that departed in January or February
```{r}
#| echo: false
flights |>
filter(month %in% c(1, 2))
```
## filter 练习
```{r}
jan1 <- flights |>
filter(month == 1 & day == 1)
```
## filter
```{r}
#| error: true
#| eval: false
flights |>
filter(month = 1)
```
## filter
```{r}
flights |>
filter(month == 1 | 2)
```
## 排序
```{r}
flights |>
arrange(year, month, day, dep_time)
```
## 排序
```{r}
flights |>
arrange(desc(dep_delay))
```
## slice
```{r}
flights |> head(n = 5)
flights |> slice(1:5)
```
## slice
```{r}
flights |>
slice_max(dep_delay, n = 5)
```
## slice
```{r}
flights |>
slice_min(dep_delay, prop = 0.005)
```
## 排序练习
根据`origin`、`dest`、`air_time`倒序排序。
```{r}
#| echo: false
flights |>
arrange(origin, dest, desc(air_time)) |>
select(origin, dest, air_time, everything())
```
## 去重
```{r}
# Remove duplicate rows, if any
flights |>
distinct()
```
## 去重
```{r}
# Find all unique origin and destination pairs
flights |>
distinct(origin, dest)
```
## 去重
```{r}
flights |>
distinct(origin, dest, .keep_all = TRUE)
```
## 欢迎讨论!{.center}
`r rmdify::slideend(wechat = FALSE, type = "public", tel = FALSE, thislink = "https://drwater.rcees.ac.cn/course/public/RWEP/@PUB/SD/")`