---
title: "Data import"
subtitle: 《区域水环境污染数据分析实践》
Data analysis practice of regional water environment pollution
author: 苏命、王为东
中国科学院大学资源与环境学院
中国科学院生态环境研究中心
date: today
lang: zh
format:
revealjs:
theme: dark
slide-number: true
chalkboard:
buttons: true
preview-links: auto
lang: zh
toc: true
toc-depth: 1
toc-title: 大纲
logo: ./_extensions/inst/img/ucaslogo.png
css: ./_extensions/inst/css/revealjs.css
pointer:
key: "p"
color: "#32cd32"
pointerSize: 18
revealjs-plugins:
- pointer
filters:
- d2
---
```{r}
#| echo: false
knitr::opts_chunk$set(echo = TRUE)
source("../../coding/_common.R")
library(tidyverse)
```
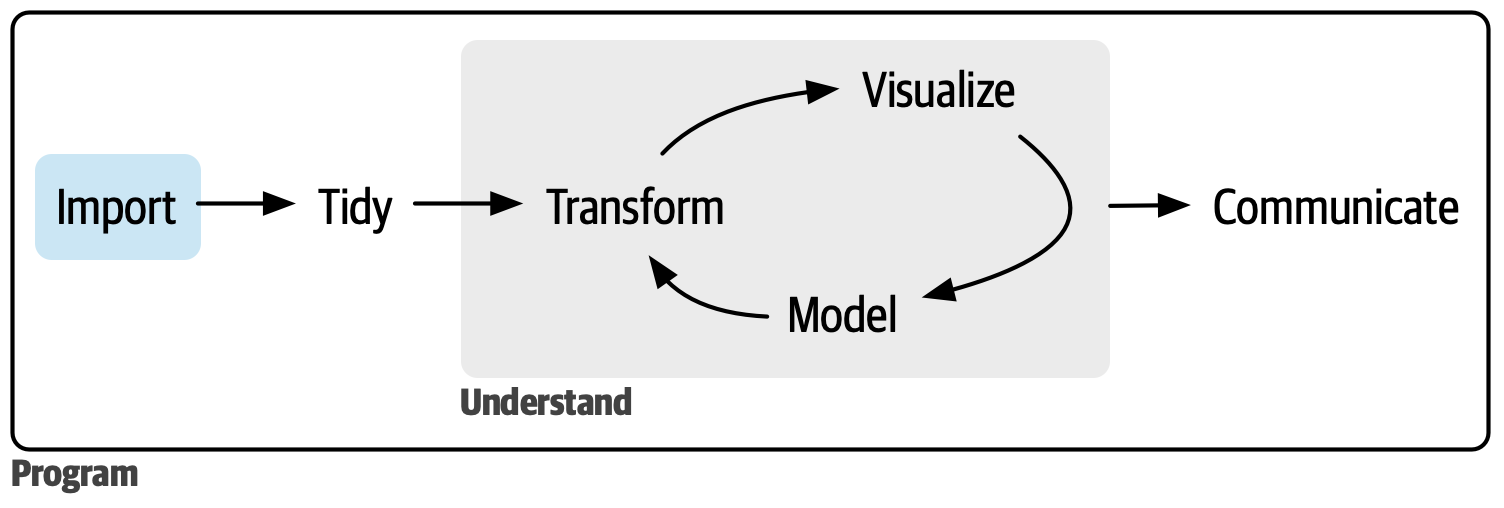
## tidyverse风格数据分析总体流程
## 导入csv数据
```{r}
read_lines("../../data/students.csv") |> cat(sep = "\n")
```
## 导入csv数据
```{r}
read_csv("../../data/students.csv") |>
knitr::kable()
```
## 读取数据
```{r}
(students <- read_csv("../../data/students.csv"))
```
## 读取数据
```{r}
#| message: false
(students <- read_csv("../../data/students.csv", na = c("N/A", "")))
```
## 列名不要有空格
```{r}
students |>
rename(
student_id = `Student ID`,
full_name = `Full Name`
)
```
## `janitor`处理空格
```{r}
#| message: false
students |> janitor::clean_names()
```
## `janitor`处理空格
```{r}
students |>
janitor::clean_names() |>
mutate(meal_plan = factor(meal_plan))
```
## `janitor`处理空格
```{r}
students <- students |>
janitor::clean_names() |>
mutate(
meal_plan = factor(meal_plan),
age = parse_number(if_else(age == "five", "5", age))
)
students
```
## 直接录入
```{r}
#| message: false
read_csv(
"The first line of metadata
The second line of metadata
x,y,z
1,2,3",
skip = 2
)
```
## 直接录入
```{r}
#| message: false
read_csv(
"# A comment I want to skip
x,y,z
1,2,3",
comment = "#"
)
```
## 指定列名
```{r}
#| message: false
read_csv(
"1,2,3
4,5,6",
col_names = c("x", "y", "z")
)
```
## 指定列的类型
```{r}
another_csv <- "
x,y,z
1,2,3"
read_csv(
another_csv,
col_types = cols(.default = col_character())
)
read_csv(
another_csv,
col_types = cols_only(x = col_character())
)
```
## 练习
```{r}
#| eval: false
read_csv("a,b\n1,2,3\n4,5,6")
read_csv("a,b,c\n1,2\n1,2,3,4")
read_csv("a,b\n\"1")
read_csv("a,b\n1,2\na,b")
read_csv("a;b\n1;3")
```
## 练习
```{r}
#| eval: false
annoying <- tibble(
`1` = 1:10,
`2` = `1` * 2 + rnorm(length(`1`))
)
```
## 批量读取
```{r}
#| message: false
sales_files <- c("../../data/01-sales.csv",
"../../data/02-sales.csv",
"../../data/03-sales.csv")
read_csv(sales_files, id = "file")
```
## 读取Excel,建议用`readxl`包
```{r}
(surveydf <- readxl::read_xlsx("../../data/survey.xlsx"))
```
## 读取Excel
```{r}
(airqualitydf <- readxl::read_xlsx("../../data/airquality.xlsx", sheet = 2))
```
## 批量读取
```{r}
sales_files <- list.files("../../data",
pattern = "sales\\.csv$", full.names = TRUE)
sales_files
```
## 写入csv
```{r}
#| warning: false
#| message: false
students
write_csv(students, "students-2.csv")
read_csv("students-2.csv")
```
## 写入Excel
```{r}
writexl::write_xlsx(students, "../../data/writexldemo.xlsx")
```
## 读取数据库,以MySQL为例
```{r}
if (FALSE) {
conn <- cctdb::get_dbconn("nationalairquality")
DBI::dbListTables(conn)
}
```
## 读取数据库,以MySQL为例
```{r}
if (FALSE) {
conn <- cctdb::get_dbconn("nationalairquality")
metadf <- tbl(conn, "metadf") |>
head(100) |>
collect()
DBI::dbDisconnect(conn)
saveRDS(metadf, file = "../../data/metadfdemo.RDS")
}
metadf <- readRDS(file = "../../data/metadfdemo.RDS")
lang <- "cn"
metadf |>
ggplot(aes(lon, lat)) +
geom_point(aes(fill = Area)) +
dwfun::theme_sci()
```
## 练习
```{r}
#| eval: false
metadf <- readxl::read_xlsx("../../data/airquality.xlsx")
dir.create("../../data/metacity2/")
metadf |>
nest(sitedf = -site) |>
mutate(flag = purrr::map2(site, sitedf,
~ writexl::write_xlsx(.y, paste0("../../data/metacity2/", .x, ".xlsx"))))
```
## 练习
```{r}
#| include: false
#| eval: false
if (FALSE) {
require(tidyverse)
conn <- cctdb::get_dbconn("nationalairquality")
metadf <- tbl(conn, "metadf") |>
collect()
DBI::dbDisconnect(conn)
metanestdf <- metadf |>
nest(citydf = -Area)
names(metanestdf$citydf) <- metanestdf$Area
writexl::write_xlsx(metanestdf$citydf, path = "../../data/meta_city.xlsx")
dir.create("../../data/metacity/")
metanestdf |>
mutate(flag = purrr::map2(Area, citydf,
~ writexl::write_xlsx(.y,
path = paste0("../../data/metacity/", .x, ".xlsx")
)))
}
```
1. 从“../../data/sales.xlsx”读取第9到13行的数据
2. 从“../../data/meta_city.xlsx”读取所有的数据,并保存至“../../data/meta_city_onetable1.xlsx”
3. 从“../../data/metacity/”读取所有的数据,并保存至“../../data/meta_city_onetable2.xlsx”
## 欢迎讨论!{.center}
`r rmdify::slideend(wechat = FALSE, type = "public", tel = FALSE, thislink = "../")`