---
title: "Data Transform"
subtitle: 《区域水环境污染数据分析实践》
Data analysis practice of regional water environment pollution
author: 苏命、王为东
中国科学院大学资源与环境学院
中国科学院生态环境研究中心
date: today
lang: zh
format:
revealjs:
theme: dark
slide-number: true
chalkboard:
buttons: true
preview-links: auto
lang: zh
toc: true
toc-depth: 1
toc-title: 大纲
logo: ./_extensions/inst/img/ucaslogo.png
css: ./_extensions/inst/css/revealjs.css
pointer:
key: "p"
color: "#32cd32"
pointerSize: 18
revealjs-plugins:
- pointer
filters:
- d2
---
```{r}
#| echo: false
knitr::opts_chunk$set(echo = TRUE)
source("../../coding/_common.R")
library(nycflights13)
library(tidyverse)
```
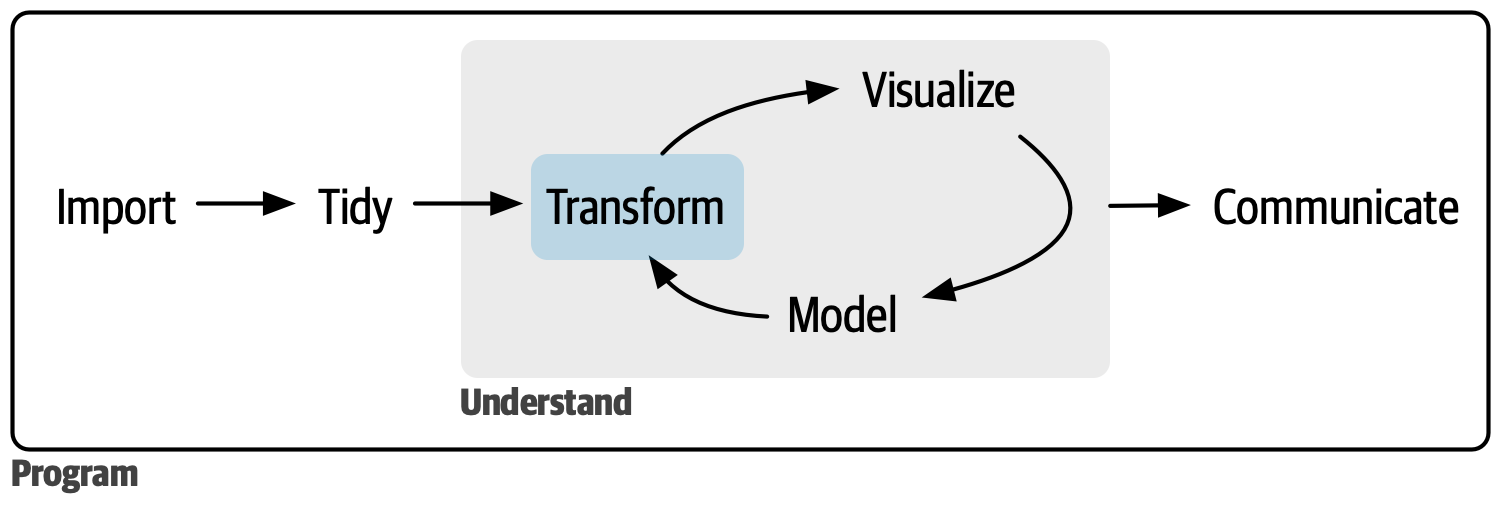
## `tidyverse`风格数据分析总体流程
## [dplyr cheatsheet](../../image/cheatsheet/data-transformation.pdf)
```{r}
#| echo: false
dwfun::ggsavep("../../image/cheatsheet/data-transformation.svg", loadit = TRUE)
```
## 查看数据
```{r}
flights
```
## 选择列
```{r}
#| results: false
flights |>
select(year, month, day)
```
## 选择列
```{r}
#| results: false
flights |>
select(year:day)
```
## 选择列
```{r}
flights |>
select(3:5)
```
## 选择列
```{r}
flights |>
select(!year:day)
```
## 选择列
```{r}
flights |>
select(-(year:day))
```
## 选择列
```{r}
flights |>
select(where(is.character))
```
## 选择列
```{r}
flights |>
select(!where(is.character)) |>
select(contains("_"))
```
## 选择列
```{r}
flights |>
select(tail_num = tailnum)
```
## 选择列
```{r}
flights |>
select(air_time, everything())
```
## 重命名
```{r}
flights |>
rename(tail_num = tailnum)
```
## 重命名
```{r}
flights |>
rename(年份 = 1) |>
rename(月份 = 2)
```
## 重命名
```{r}
flights |> select(1:4) |> head(n = 3)
# 重命名
flights |> select(1:4) |> head(n = 3) |>
rename_all(~c("c1", "c2", "c3", "c4"))
```
## 重命名
```{r}
flights |> select(1:4) |> head(n = 3)
# 重命名
flights |> select(1:4) |> head(n = 3) |>
rename_all(toupper)
```
## 重命名
```{r}
flights |> select(1:4) |> head(n = 3)
# 重命名
flights |> select(1:4) |> head(n = 3) |>
rename_all(~paste0(toupper(.), "_NEW"))
```
## 练习
将含有下划线的列名中的下划线去掉。
```{r}
flights |> select(1:4) |> head(n = 3)
```
## 练习
将`airqualitydf`中列名的单位信息去除(前5列)。
```{r}
airqualitydf <- readxl::read_xlsx("../../data/airquality.xlsx", sheet = 2)
airqualitydf |> select(1:5)
```
## `filter`
```{r}
flights |>
filter(dep_delay > 120)
```
## filter 练习
Flights that departed on January 1.
```{r}
#| echo: false
flights |>
filter(month == 1 & day == 1)
```
## filter 练习
Select flights that departed in January or February
```{r}
#| echo: false
flights |>
filter(month %in% c(1, 2))
```
## filter 练习
```{r}
jan1 <- flights |>
filter(month == 1 & day == 1)
```
## filter
```{r}
#| error: true
#| eval: false
flights |>
filter(month = 1)
```
## filter
```{r}
flights |>
filter(month == 1 | 2)
```
## 排序
```{r}
flights |>
arrange(year, month, day, dep_time)
```
## 排序
```{r}
flights |>
arrange(desc(dep_delay))
```
## slice
```{r}
flights |> head(n = 5)
flights |> slice(1:5)
```
## slice
```{r}
flights |>
slice_max(dep_delay, n = 5)
```
## slice
```{r}
flights |>
slice_min(dep_delay, prop = 0.005)
```
## 排序练习
根据`origin`、`dest`、`air_time`倒序排序。
```{r}
#| echo: false
flights |>
arrange(origin, dest, desc(air_time)) |>
select(origin, dest, air_time, everything())
```
## 去重
```{r}
# Remove duplicate rows, if any
flights |>
distinct()
```
## 去重
```{r}
# Find all unique origin and destination pairs
flights |>
distinct(origin, dest)
```
## 去重
```{r}
flights |>
distinct(origin, dest, .keep_all = TRUE)
```
## 计数
```{r}
flights |>
count(origin, dest, sort = TRUE)
```
## 计数-练习
统计每月的航班数量。
```{r}
#| echo: false
flights |>
count(year, month, sort = TRUE)
```
## 计算新变量
```{r}
flights |>
mutate(
gain = dep_delay - arr_delay,
speed = distance / air_time * 60
)
```
## 计算新变量
```{r}
flights |>
mutate(
gain = dep_delay - arr_delay,
speed = distance / air_time * 60,
.before = 1
)
```
## 计算新变量
```{r}
flights |>
mutate(
gain = dep_delay - arr_delay,
speed = distance / air_time * 60,
.after = day
)
```
## 计算新变量
```{r}
flights |>
mutate(
gain = dep_delay - arr_delay,
hours = air_time / 60,
gain_per_hour = gain / hours,
.keep = "used"
)
```
## 列排序
```{r}
flights |>
relocate(time_hour, air_time)
```
## 列排序
```{r}
#| results: false
flights |>
relocate(year:dep_time, .after = time_hour)
flights |>
relocate(starts_with("arr"), .before = dep_time)
flights |>
select(starts_with("arr"), everything())
```
## 练习
计算目的地为IAH,按飞行速度排序的表格,保留year:day, `dep_time`, carrier, flight与speed列。
```{r}
flights |>
filter(dest == "IAH") |>
mutate(speed = distance / air_time * 60) |>
select(year:day, dep_time, carrier, flight, speed) |>
arrange(desc(speed))
```
## 练习
计算目的地为IAH,按飞行速度排序的表格,保留year:day, `dep_time`, carrier, flight与speed列。
```{r}
#| results: false
flights1 <- filter(flights, dest == "IAH")
flights2 <- mutate(flights1, speed = distance / air_time * 60)
flights3 <- select(flights2, year:day, dep_time, carrier, flight, speed)
arrange(flights3, desc(speed))
```
## 练习
计算目的地为IAH,按飞行速度排序的表格,保留year:day, `dep_time`, carrier, flight与speed列。
```{r}
flights |>
filter(dest == "IAH") |>
mutate(speed = distance / air_time * 60) |>
select(year:day, dep_time, carrier, flight, speed) |>
arrange(desc(speed))
```
## 分组统计
```{r}
library(tidyverse)
mtcars %>%
group_by(cyl) %>%
summarize(n = n())
```
## 分组统计
```{r}
flights |>
group_by(month)
```
## 分组统计
```{r}
flights |>
group_by(month) |>
summarize(
avg_delay = mean(dep_delay)
)
```
## 分组统计
```{r}
flights |>
group_by(month) |>
summarize(
avg_delay = mean(dep_delay, na.rm = TRUE)
)
```
## 分组统计
```{r}
flights |>
group_by(month) |>
summarize(
avg_delay = mean(dep_delay, na.rm = TRUE),
n = n()
)
```
## 分组统计
```{r}
flights |>
group_by(dest) |>
slice_max(arr_delay, n = 1) |>
relocate(dest)
```
## 分组统计
```{r}
flights |>
filter(dest == "IAH") |>
group_by(year, month, day) |>
summarize(
arr_delay = mean(arr_delay, na.rm = TRUE)
)
```
## 分组
```{r}
daily <- flights |>
group_by(year, month, day)
daily
```
## 分组统计
```{r}
daily_flights <- daily |>
summarize(n = n())
```
## 分组统计
```{r}
#| results: false
daily_flights <- daily |>
summarize(
n = n(),
.groups = "drop_last"
)
```
## 删除分组
```{r}
daily |> ungroup()
```
## 删除分组
```{r}
daily |>
ungroup() |>
summarize(
avg_delay = mean(dep_delay, na.rm = TRUE),
flights = n()
)
```
## 分组统计
```{r}
flights |>
summarize(
delay = mean(dep_delay, na.rm = TRUE),
n = n(),
.by = month
)
```
## 分组统计
```{r}
flights |>
summarize(
delay = mean(dep_delay, na.rm = TRUE),
n = n(),
.by = c(origin, dest)
)
```
## 练习
```{r}
df <- tibble(
x = 1:5,
y = c("a", "b", "a", "a", "b"),
z = c("K", "K", "L", "L", "K")
)
df
```
```{r}
#| eval: false
df |> arrange(y)
```
## 练习
```{r}
#| echo: false
df
```
```{r}
#| eval: false
df |>
group_by(y) |>
summarize(mean_x = mean(x))
```
## 练习
```{r}
#| echo: false
df
```
```{r}
#| eval: false
df |>
group_by(y, z) |>
summarize(mean_x = mean(x))
```
## 练习
```{r}
#| echo: false
df
```
```{r}
#| eval: false
df |>
group_by(y, z) |>
summarize(mean_x = mean(x), .groups = "drop")
```
## 练习
```{r}
#| echo: false
df
```
```{r}
#| eval: false
df |>
group_by(y, z) |>
summarize(mean_x = mean(x))
df |>
group_by(y, z) |>
mutate(mean_x = mean(x))
```
## 练习
- 计算不同采样点的平均CO浓度、最大CO浓度、最小CO浓度、中位数CO浓度(`CO_mg/m3`)。
- 计算各小时全国的平均CO浓度、最大CO浓度、最小CO浓度、中位数CO浓度(`CO_mg/m3`)。
- 计算不同采样点各小时的平均CO浓度、最大CO浓度、最小CO浓度、中位数CO浓度(`CO_mg/m3`)。
- 计算各采样点中CO浓度小于全国平均CO浓度的占比。
- 找出全国各采样点中CO浓度小于全国平均CO浓度的占比最高的10个采样点。
```{r}
airqualitydf <- readxl::read_xlsx("../../data/airquality.xlsx",
sheet = 2)
```
## 练习
按月统计dep_delay最大的3个航班的航班号(flight),用逗号连接。
```{r}
#| echo: false
flights |>
group_by(year, month) |>
slice_max(dep_delay, n = 3) |>
summarize(flight = paste(paste0(carrier, flight), collapse = ", ")) |>
knitr::kable()
```
## 数据变形示意图
```{r}
billboard
knitr::include_graphics("../../image/tidy-data/variables.png", dpi = 270)
```
## 数据变形
```{r}
billboard |>
pivot_longer(
cols = starts_with("wk"),
names_to = "week",
values_to = "rank",
values_drop_na = TRUE
)
```
## 数据变形
```{r}
billboard_longer <- billboard |>
pivot_longer(
cols = starts_with("wk"),
names_to = "week",
values_to = "rank",
values_drop_na = TRUE
) |>
mutate(
week = parse_number(week)
)
billboard_longer
```
## 练习
```{r}
#| echo: false
df <- tribble(
~id, ~bp1, ~bp2,
"A", 100, 120,
"B", 140, 115,
"C", 120, 125
)
df
```
将以上数据(`df`)转换为如下形式。
```{r}
#| echo: false
df |>
pivot_longer(
cols = bp1:bp2,
names_to = "measurement",
values_to = "value"
)
```
## 练习
请转换如下`iris`数据。
```{r}
#| echo: false
as_tibble(head(iris, n = 3))
cat("转为如下形式:")
iris |>
pivot_longer(cols = c(Sepal.Length,
Sepal.Width,
Petal.Length,
Petal.Width),
names_to = "flower_attr",
values_to = "attr_value") |>
head()
```
## 数据变形示意图2
```{r}
who2
knitr::include_graphics("../../image/tidy-data/multiple-names.png", dpi = 270)
```
## 数据变形
```{r}
who2 |>
pivot_longer(
cols = !(country:year),
names_to = c("diagnosis", "gender", "age"),
names_sep = "_",
values_to = "count"
)
```
## 数据变形示意图
```{r}
household
knitr::include_graphics("../../image/tidy-data/names-and-values.png", dpi = 270)
```
## 数据变形
```{r}
household |>
pivot_longer(
cols = !family,
names_to = c(".value", "child"),
names_sep = "_",
values_drop_na = TRUE
)
```
## 查看数据
```{r}
cms_patient_experience
```
## 查看数据
```{r}
cms_patient_experience |>
distinct(measure_cd, measure_title)
```
## 数据变形(变宽)
```{r}
cms_patient_experience |>
pivot_wider(
names_from = measure_cd,
values_from = prf_rate
)
```
## 数据变形(变宽)
```{r}
cms_patient_experience |>
pivot_wider(
id_cols = starts_with("org"),
names_from = measure_cd,
values_from = prf_rate
)
```
## 练习
```{r}
df <- tribble(
~id, ~measurement, ~value,
"A", "bp1", 100,
"B", "bp1", 140,
"B", "bp2", 115,
"A", "bp2", 120,
"A", "bp3", 105
)
```
变形成如下形式:
```{r}
#| echo: false
df |>
pivot_wider(
names_from = measurement,
values_from = value
)
```
## 练习:变宽
```{r}
df <- tribble(
~id, ~measurement, ~value,
"A", "bp1", 100,
"A", "bp1", 102,
"A", "bp2", 120,
"B", "bp1", 140,
"B", "bp2", 115
)
```
## 练习
```{r}
df |>
pivot_wider(
names_from = measurement,
values_from = value
)
```
## 练习
```{r}
df |>
group_by(id, measurement) |>
summarize(n = n(), .groups = "drop") |>
filter(n > 1)
```
## nest,套嵌数据框
```{r}
#| echo: false
df <- tibble(x = c(1, 1, 1, 2, 2, 3), y = 1:6, z = 6:1)
df
```
```{r}
df %>% nest(data = c(y, z))
```
## nest,套嵌数据框
Specify variables to nest by (rather than variables to nest) using `.by`
```{r}
df %>% nest(.by = x)
```
## nest,套嵌数据框
In this case, since `...` isn't used you can specify the resulting column name with `.key`
```{r}
df %>% nest(.by = x, .key = "cols")
```
## nest,套嵌数据框
Use tidyselect syntax and helpers, just like in `dplyr::select()`
```{r}
df %>% nest(data = any_of(c("y", "z")))
```
## nest,套嵌数据框
`...` and `.by` can be used together to drop columns you no longer need,
or to include the columns you are nesting by in the inner data frame too.
This drops `z`:
```{r}
df %>% nest(data = y, .by = x)
```
## nest,套嵌数据框
This includes `x` in the inner data frame:
```{r}
df %>% nest(data = everything(), .by = x)
```
## nest,套嵌数据框
Multiple nesting structures can be specified at once
```{r}
iris %>%
nest(petal = starts_with("Petal"), sepal = starts_with("Sepal"))
```
## nest,套嵌数据框
```{r}
iris %>%
nest(width = contains("Width"), length = contains("Length"))
```
## nest,套嵌数据框
Nesting a grouped data frame nests all variables apart from the group vars
```{r}
fish_encounters
fish_encounters %>%
dplyr::group_by(fish) %>%
nest()
```
## nest,套嵌数据框
That is similar to `nest(.by = )`, except here the result isn't grouped
```{r}
fish_encounters %>%
nest(.by = fish)
```
## nest,套嵌数据框
Nesting is often useful for creating per group models
```{r}
mtcars %>%
nest(.by = cyl) %>%
dplyr::mutate(models = lapply(data, function(df) lm(mpg ~ wt, data = df)))
```
## 练习
```{r}
#| echo: false
(airqualitydf <- readxl::read_xlsx("../../data/airquality.xlsx",
sheet = 2))
```
```{r}
airqualitydf
airqualitynestdf <- airqualitydf |>
nest(sitedf = -site)
```
## `nest`与`group_by`联用
```{r}
#| echo: false
iris %>%
group_by(Species) %>%
nest(.key = "spdf")
```
## unnest
```{r}
airqualitynestdf |> unnest(sitedf)
```
## `purrr`包
- map():依次应用一元函数到一个序列的每个元素上,基本等同 lapply()
- map2():依次应用二元函数到两个序列的每对元素上
- pmap():应用多元函数到多个序列的每组元素上,可以实现对数据框逐行迭代
- map 系列默认返回列表型,可根据想要的返回类型添加后缀:_int, _dbl, _lgl, _chr, _df, 甚至可以接着对返回的数据框df做行/列合并:_dfr, _dfc
- 如果只想要函数依次作用的过程,而不需要返回结果,改用 walk 系列即可
- 所应用的函数,有 purrr公式风格简写(匿名函数),支持一元,二元,多元函数
- purrr 包中的其它有用函数
## `purrr`包
- `map_chr(.x, .f)`: 返回字符型向量
- `map_lgl(.x, .f)`: 返回逻辑型向量
- `map_dbl(.x, .f)`: 返回实数型向量
- `map_int(.x, .f)`: 返回整数型向量
- `map_dfr(.x, .f)`: 返回数据框列表,再 bind_rows 按行合并为一个数据框
- `map_dfc(.x, .f)`: 返回数据框列表,再 bind_cols 按列合并为一个数据框
## `purrr`包-cheatsheet
```{r}
dwfun::ggsavep("../../image/cheatsheet/purrr.svg", loadit = TRUE)
```
[purrr](../../image/cheatsheet/purrr.pdf)
## `purrr`包
生成从1到10的10组随机数,每组随机数个数为100,均值依次为1到10,标准差为1,并存储在数据框中。
```{r}
res <- list()
for (i in 1:10) {
res[[i]] <- tibble(随机数 = rnorm(n = 100, mean = i, sd = 1))
}
res
```
## `purrr`包
生成从1到10的10组随机数,每组随机数个数为100,均值依次为1到10,标准差为1,并存储在数据框中。
```{r}
1:10 |>
purrr::map(~tibble(随机数 = rnorm(n = 100, mean = .x, sd = 1)))
```
## purrr
```{r}
library(purrr)
mtcars |>
split(mtcars$cyl) |> # from base R
map(\(df) lm(mpg ~ wt, data = df)) |>
map(summary) %>%
map_dbl("r.squared")
```
## 练习:
计算每月最后一个周六的航班数:
```{r}
flights
```
## `tidyr` + `purrr`包
任务:展示不同城市间的大气指标散点图
```{r}
(airqualitydf <- readxl::read_xlsx("../../data/airquality.xlsx",
sheet = 2))
```
## join
Perform left join
```{r}
(df1 <- data.frame(id = 1:5, value1 = letters[1:5]))
(df2 <- data.frame(id = c(2, 4, 6), value2 = LETTERS[1:3]))
left_join(df1, df2, by = "id")
```
## left join
Create sample data frames with non-matching rows
```{r}
(df1 <- data.frame(id = 1:5, value1 = letters[1:5]))
(df2 <- data.frame(id = c(2, 4, 6), value2 = LETTERS[1:3]))
left_join(df2, df1, by = "id")
```
## left join
Create sample data frames with multiple columns
```{r}
df1 <- data.frame(id1 = c(1, 2, 3), id2 = c("A", "B", "C"), value1 = letters[1:3])
df2 <- data.frame(id1 = c(2, 3, 4), id2 = c("B", "C", "D"), value2 = LETTERS[1:3])
# Perform left join
left_join(df1, df2, by = c("id1", "id2"))
```
## right join
```{r}
(df1 <- data.frame(id = 1:5, value1 = letters[1:5]))
(df2 <- data.frame(id = c(2, 4, 6), value2 = LETTERS[1:3]))
# Perform right join
right_join(df1, df2, by = "id")
```
## inner join
```{r}
# Create sample data frames
(df1 <- data.frame(id = 1:5, value1 = letters[1:5]))
(df2 <- data.frame(id = c(2, 4, 6), value2 = LETTERS[1:3]))
# Perform inner join
inner_join(df1, df2, by = "id")
```
## full join
```{r}
# Create sample data frames
(df1 <- data.frame(id = 1:5, value1 = letters[1:5]))
(df2 <- data.frame(id = c(2, 4, 6), value2 = LETTERS[1:3]))
# Perform inner join
full_join(df1, df2, by = "id")
```
## semi join
Create sample data frames
```{r}
(df1 <- data.frame(id = 1:5, value1 = letters[1:5]))
(df2 <- data.frame(id = c(2, 4, 6), value2 = LETTERS[1:3]))
# Perform semi join
semi_join(df1, df2, by = "id")
```
## 欢迎讨论!{.center}
`r rmdify::slideend(wechat = FALSE, type = "public", tel = FALSE, thislink = "https://drwater.rcees.ac.cn/course/public/RWEP/@PUB/SD/")`